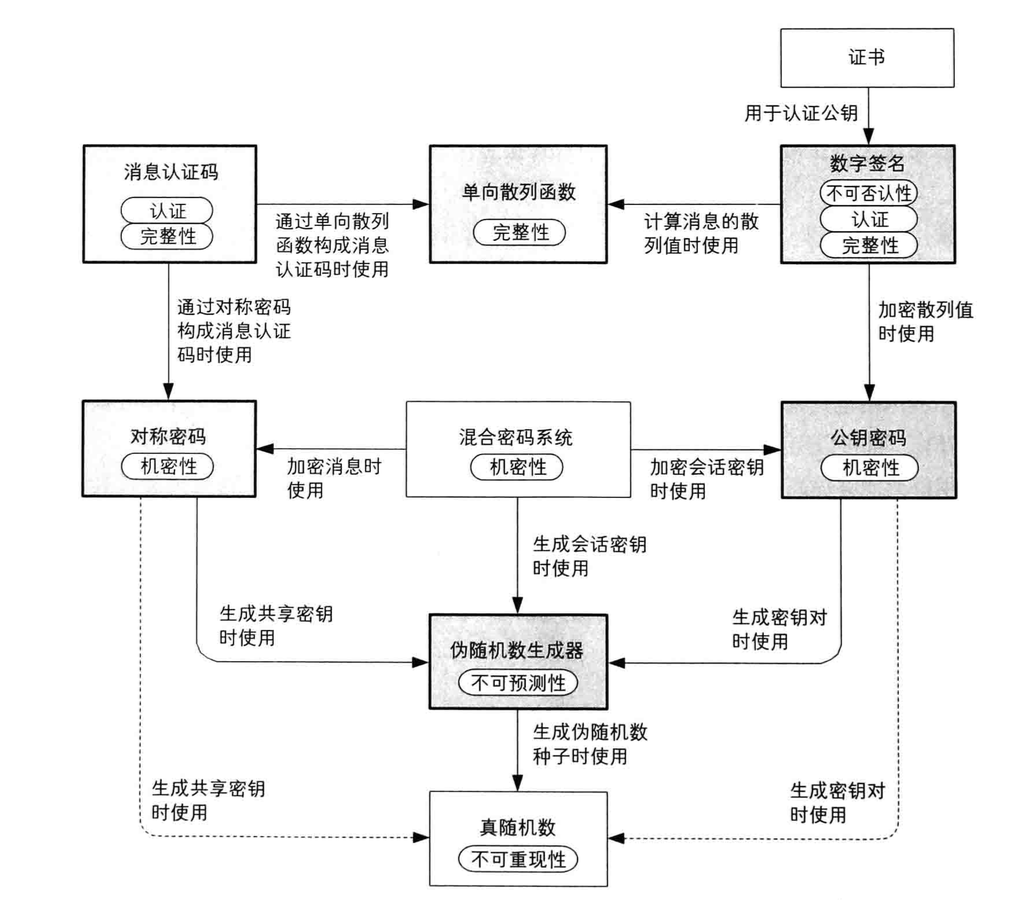
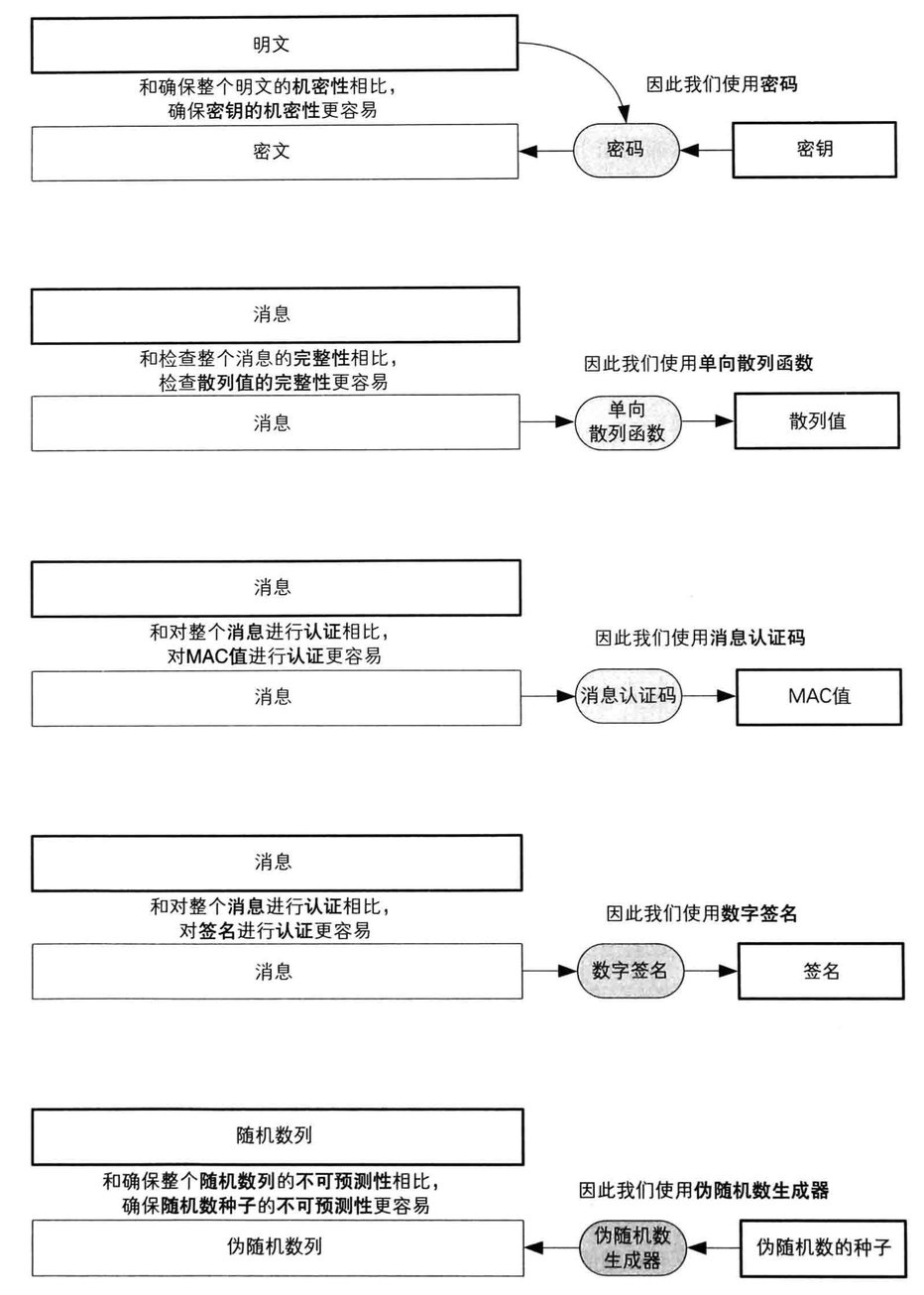
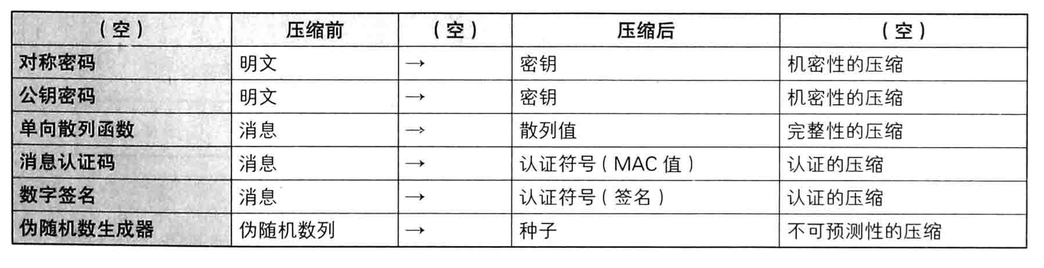
Web Audio API Advance
一个简单的、典型的web audio工作流是这样的:
- 创建音频环境对象(AudioContext)。
- 在音频环境对象AudioContext中,创建音源。例如
<audio>,振荡器(oscillator),源。 - 创建效果节点(effectNode),例如分析、增益、混响、双二阶滤波器、平移、压缩等。
- 选择最终的音源目的地,例如你的系统扬声器。
- 连接源到效果节点,以及效果节点到输出终端。

简单来说,Web Audio API提供了一个简单强大的机制来实现控制web应用程序的音频内容,但是Web Audio API并不会取代<audio>,而可以把它看做是<audio>的补充,就好像<img>和<canvas>的共存关系。你用来实现音频的方式取决于你的需求的复杂程度,如果只是简单的音轨播放,那么<audio>足够了。
这里首先来明确两个概念。
1. AudioContext – 音频环境对象
W3C描述如下:
This interface represents a set of AudioNode objects and their connections. It allows for arbitrary routing of signals to the AudioDestinationNode (what the user ultimately hears). Nodes are created from the context and are then connected together. In most use cases, only a single AudioContext is used per document.
大致意思是这个接口是音频节点和节点之间连接关系的集合。他允许信号经过任意的路由连接到目的节点(音频播放设备节点)上。节点都是通过音频环境(AudioContext)创建的,然后连接在一起。在大多数情况下,一个文档只需要一个音频环境。
|
|
可以看出AudioContext相当于一个容器,各类音频节点,及节点间的连接方式都需要AudioContext的实例对象来创建。
2. AudioNode – 音频节点
W3C中描述如下:
AudioNodes are the building blocks of an AudioContext. This interface represents audio sources, the audio destination, and intermediate processing modules.
音频节点是一个音频环境的基础模块。这些节点可以是音频源节点,音频播放设备节点,也可以是中间处理模块。
3. Demo构建流程
先来看一个简单的音频模型,音频直接连接到播放设备节点播放。
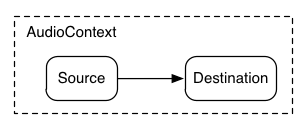
再来看一套专业的音效合成处理图:
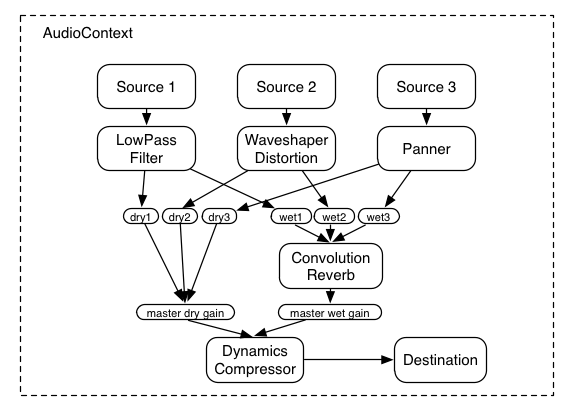
是不是很厉害,好,那么接下来我们讲点简单的……
3.1 构建AudioContext对象
首先,需要构建一个AudioContext实例,来创建一个音频环境容器。
|
|
3.2 创建音源AudioSource
现在有了环境的实例对象,前面也提到这个对象非常有用,接下来就是用这个实例整一个音源。音源可以用以下几种方式创建/获取:
- 从PCM(Pulse Code Modulation,脉冲编码调制)数据构建:这个PCM数据是啥玩意,怎么来?简单的说:首先可以通过XMLHttpRequest获取被支持的音频格式的文件(比如x.mp3),然后利用AudioContext对象中的方法对文件进行解码后获得的数据。下文中提到的自产demo ,就是利用这种方式获取音源的。AudioContext提供了解密被支持的音频格式的多种方法: AudioContext.createBuffer(), AudioContext.createBufferSource(), 以及 AudioContext.decodeAudioData().
- 利用AudioContext对象直接生产音频节点,比如振荡器oscillator。具体API:AudioContext.createOscillator()
|
|
- 来自HTML音频元素,如我们熟悉的
<video>或者<audio>.具体API: AudioContext.createMediaElementSource()
|
|
- 直接来自于WebRTC,MediaStream。如摄像头、麦克风。具体API: AudioContext.createMediaStreamSource()。这种方式可以看下MDN提供的Demo:the Voice-change-O-matic live及Demo源码
3.3 连接输入输出
接下来需要创建改变音效的节点,并将这些节点连接起来,最终通过默认输出设备(通常是是设备扬声器)实质输出声音。AudioContext.destination就是最后需要连接的输出设备节点。
|
|
当然还有很多增益相关的节点,比如:
|
|
如果你一股脑添加了如上的节点,就会得到下面的音频节点图。这些节点都可以做对应的设置,来达到复杂的音频调节效果,这里就不做展开了,因为我也展不开……
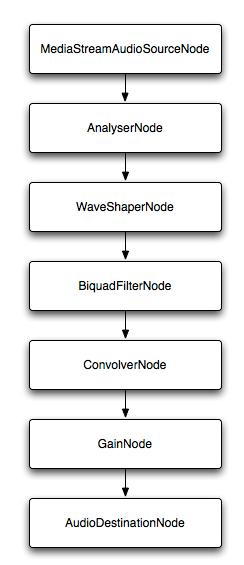
3.4 设置音调、声音大小并播放
终于到最后了,下面简单的做个设置就开始放吧:
|
|
具体接口请参考Web_Audio_API
3.5 自产demo
下面就上一个简单的demo,过程是利用XHR获取一个mp3文件,解码后播放,加了调节音量的按钮。
PS:
- AudioSampleLoader这个库可以帮你简化XHR/buffer的操作。
- Web Audio API的具体资料可以参考:Web_Audio_API